
Parametric estimation vs identification

What nonparametric identification is and why it matters — even if we estimate parametric models.

I saw a post on LinkedIn that asked (I’m paraphrasing): “Why do we care about things being nonparametric if, in practice, we’re just going to use parametric estimation?” So, this post is my little attempt to make the distinction and the case for why the existence of a nonparametric estimator matters, even if we don’t use it.
First, definitions because the nomenclature’s funky. Parametric refers to a finite-dimensional parameter space, e.g., the coefficients in a linear regression. Nonparametric refers to an infinite-dimensional parameter space, e.g., a conditional mean function, t(x) = E[Y|X=x]. I say it’s funky because, in both cases, we’re talking about “parameters.” It’s just about whether they are finite or infinite-dimensional parameters.
When we say that a model is “nonparametrically identified,” we mean that there is a mapping between the data’s distribution and the parameter t that does not depend on t belonging to a finite-dimensional part of the parameter space.
In practice, this means there is a mapping between the data and t, even without an assumption about the functional form of t or the data’s distribution.
For example, the conditional mean t(x) = E[Y|X=x] is nonparametrically identified if we observe data on (Y,X) because there is a mapping between the distribution of (Y,X) and t(x). The mapping is just the definition of a conditional expectation:
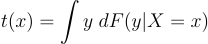
But now, let’s consider the same parameter in another setting. So, t(x) = E[Y|X=x], but now, let’s say we don’t observe (Y,X). Instead, we observe (Y*,X) where Y* = max{0, Y}. We don’t observe Y when it’s negative.
Because: Y = max{0,Y} + min{0, Y}, we can write t(x) as:
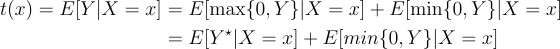
The first term is nonparametrically identified. We know the distribution of (Y*, X) from the data, and we can use the usual mapping of that distribution to the conditional expectation. But, without further assumption, the distribution of Y when it is positive tells us nothing about the distribution of Y when it is negative, so:
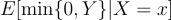
is not identified from the distribution of (Y*, X). There is no mapping between this distribution and this parameter. So, t(x) is not nonparametrically identified when we only observe (Y*, X).
However… suppose we make a parametric assumption. For example, suppose:
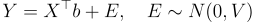
Where E is independent of X. Now, the distribution of (Y*, X) is informative about the distribution of (Y, X). Because we can write Y* as:
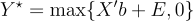
And
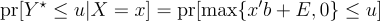
Moving u around will trace out b and the variance parameter of E. Why does this work? Because we’ve specified a relationship between the behavior of Y conditional on Y being positive and the way Y behaves when it’s negative. The data doesn’t reveal this relationship. Our parametric assumption imposes it.
Maybe this model is motivated by some reasonable model of the world, but it’s probably not. It’s just a functional form. There is a mapping between the data and the parameter of interest because the functional form assumptions fill the gap between the data and what we want to know.
So, let’s look at why nonparametric identification is so important:
When we observe (Y,X), we are nonparametrically identified. Even if we just run a linear model in estimation, we know that the regression is trying to fit variation that does precisely reveal what we want to know, independent of the functional form assumption.
When we only observe (Y*,X), t(x) is not nonparametrically identified. Our functional form tells us where the parameter of interest is in the data. If we choose another parametric form, another part of the data will determine the parameter of interest. The functional form determines the variation we use to get at the parameter of interest.
Nonparametric identification matters, and we should doubt analysis based on parametrically identified parameters.
For example, in the problem above, it’s worth asking whether we could learn what we want to know via a quantile regression method. Some quantiles are nonparametrically identified even when we only observe (Y*, X). If a quantile-based model can answer the relevant questions, then it’s an appealing alternative because it doesn’t depend on functional form for identification.
Estimation is a separate problem. Nonparametric estimators are mostly fictitious, a story we tell ourselves. We promise that we’d make the model more flexible if the sample were larger. It’s a lie, of course, but we always have a small sample, so there’s never any evidence against us. We always end up having a finite set of parameters.
Parametric estimation is fine, but our models should not require the specific parametric form for the data to be informative about the parameter of interest.
Thanks for reading!
Zach
Connect at: https://linkedin.com/in/zlflynn
If you want my help with any Experimentation, Analytics, etc. problem, click here.