
Monotone Trends for the Difference in Difference Setup

Bounding Treatment Effects with a weaker, more credible, ordinal version of the classic “parallel trends” assumption

Suppose we observe two time periods {1, 2} and two groups of units {A, B}.
In period 1, both A and B are untreated.
In period 2, group B is treated while A remains untreated.
This is the classic difference-in-difference setup — the fallback of every data scientist in the industry — because, hey, we probably didn’t roll out to every country, so let’s use Poland as the control group for the US…
As you might imagine, the assumptions we need to do this are strong (read: “definitely not true”). Is there a way to use a dataset like this with much weaker assumptions — and still learn something?
Parallel Trends
Let M(t, g, z) be the expected value of the metric in period t for group g that receives treatment z.
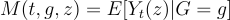
The treatment effect we want to identify is the treatment’s causal effect on the treated: M(2, B, 1) — M(2, B, 0).
The standard difference-in-difference analysis is based on the parallel trends assumptions, which is:
Assumption (Parallel Trends): M(2,g,0) — M(1,g,0) = D for all g. The change from period 1 to 2 is the same regardless of group membership but for the treatment status change.
Given Parallel Trends:
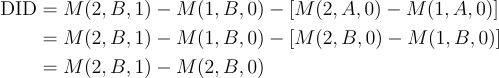
So, we can identify the treatment effect with the usual difference-in-difference statistic.
But this assumption is strong for two reasons:
It’s a cardinal assumption. The change in the mean needs to be the same in magnitude for each group. Of course, we can also cast this in log scale, etc, but in either case, it’s an assumption about the actual size of the change.
There are such enormous differences between the typical groups used in practice (frequently in the biz: countries) that it is difficult to believe M(2, B, 0) — M(1, B, 0) = M(2, A, 0) — M(1, A, 0).
What weaker assumptions could we use in this same setup?
Monotone Trends
An intuitive relaxation of this identification assumption is that the sign of the difference between periods 2 and 1 is the same for both groups:
Assumption (Monotone Trends). (M(2,A,0) — M(1,A,0))(M(2, B, 0) — M(1, B, 0)) > 0.
This assumption gives us one-sided bounds on the treatment effect.
For example,
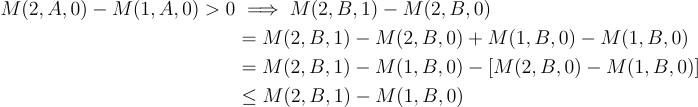
So, under Monotone Trends, we can sign the bias of the pre-post estimator.
This doesn’t help very much by itself. It tells us we can use pre-post estimators to find the upper or lower bound on the treatment effect, but we want to bound both sides to know whether the effect is positive or negative.
H-Monotone Trends
However, if we have a covariate and can apply Monotone Trends to all covariate levels, we can sign treatment effects.
Suppose we have a discrete covariate H (discreteness is for exposition — not required). Let M(t, g, z, h) denote the expected value of a metric in period t, for treatment or control group g, under treatment z, in subgroup h (well, that’s a lot of qualifications).
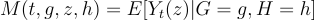
Assumption (H-Monotone Trends). [M(2, A, 0, h) — M(1, A, 0, h)][M(2, B, 0, h) — M(1, B, 0, h)] ≥ 0 holds for all levels h in the support of H.
Then, for all covariate levels h where M(2, A, 0, h) — M(1, A, 0, h) > 0:
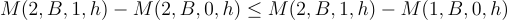
And for all subgroups where M(2, A, 0, h) — M(1, A, 0, h) < 0:
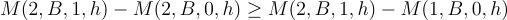
We still don’t have bounds on M(2, B, 1) — M(2, B, 0) because — without further assumption — we don’t know that the upper or lower bound isn’t +- infinity for these subgroups. So we can’t integrate up and get nontrivial bounds. Therefore, we need to bound the worst case.
Assumption (Boundedness). L ≤ M(2, B, 1, h) — M(2, B, 0, h) ≤ U.
Tip: The usual way to justify the Boundness assumption is to say that the metric we’re measuring takes values on a bounded interval, e.g., binary or Winsorized data.
Because the usual way of getting {L, U} is to use the boundedness of the random variable, I’ll assume that L ≤ M(2, B, 1, h) — M(1, B, 0, h) ≤ U as well to make the expressions simpler but that is not necessary.
Now, we can integrate across H to get bounds on the treatment on the treated because:
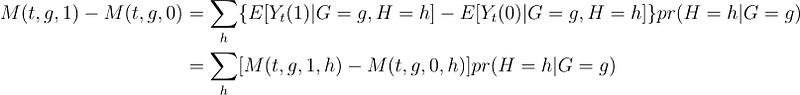
So, the lower and upper bounds are formed by taking the lower or upper bound from each covariate-level bound on M(2, B, 1, h) — M(2,B,0,h).
The lower bound is:
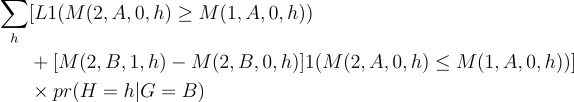
The upper bound is:
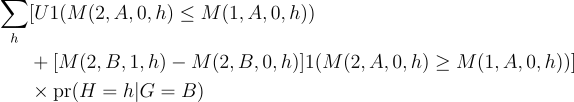
These give upper and lower bounds on the treatment effect under — what I’d argue — are more plausible assumptions than traditional diff-in-diff.
To show that the bounds can sign the effect, suppose the underlying metric is binary so that L = -1 and U = +1. Then the lower bound is at most:
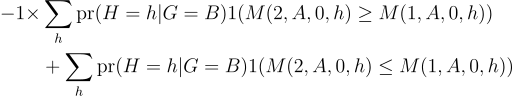
It’s possible the probability of being in a group where M(2, A, 0, h) ≤ M(1, A, 0, h) is greater than 50%, in which case the bound is positive.
So, the bounds can sign the treatment effect: M(2, B, 1) — M(2, B, 0).
Is H-monotone trends strictly weaker than parallel trends?
No. Parallel trends does not assume anything about another covariate, so it’s possible that requiring monotone differences across all covariate levels doesn’t hold and parallel trends does.
However — in general—with endless caveats — ordinal assumptions are more plausible than cardinal assumptions. Ordinal assumptions require that a kind of relationship holds (the untreated group’s time trend is in the same direction as the treated group’s would have been). Cardinal assumptions restrict the exact magnitude of the relationship (the time trend would have been the same without the intervention).
Conclusions and Caveats
When we can’t run experiments, the difference-in-difference setup seems convincing enough. We interpret any increase in the treated group relative to some untreated group as the treatment’s effect.
While it makes intuitive sense, interpreting the result as the treatment effect requires strong assumptions that it’d be better to avoid.
We can put nontrivial bounds on the treatment effect with an appealing relaxation of parallel trends.
The caveat is that, in practice, the bounds may be wide and not very informative (do you like how I have saved that for the end?). We need a covariate with a lot of variety in how the various conditional means shifted so that some increased and some decreased. Finding such a covariate can be tricky in practice because, frequently, everything goes up or down.
Thanks for reading!
Zach
Connect at: https://linkedin.com/in/zlflynn
Take my Udemy course!: Identifying Causal Effects for Data Scientists
If you want my help with any Experimentation, Analytics, etc. problem, click here.