
Making Social Decisions from Experiments: Convincing the Skeptic


How do we decide what to do given that we ran an A-B experiment with success metric Y? There are three common approaches here. Usually, the actual decision rule is some combination of these three plus the gut factor:
Hypothesis testing. We will stick with the status quo (A) unless there is sufficient evidence to switch to B. I’m collapsing both Frequentist approaches and decisions based on “Bayesian” credible intervals here. They are effectively the same.
Bayesian. In this approach, we are literally Bayesian. We have a prior belief, we observe some data, and we maximize the expected value of the metric given the change in our information set by choosing {A,B}. I say literally (in italics) because I’m assuming you actually really believed the prior before seeing the data and aren’t just choosing a weighting function, an uninformative prior, etc.
Ignore Statistical Uncertainty. Just ship if the mean in B is bigger than the mean in A. Don’t listen to the stats people. If they try to talk back to you, you can even cite some papers that say this is sort of optimal under some criteria (I won’t link them out of solidarity with the stats people).
The Bayesian decision rule has sort of the most intuitive theory from a decision-making perspective, but whose beliefs do we use? And, for the approach to enjoy any special advantages it has to be real beliefs. So, we can’t really set this centrally/automatically. Each experiment would require someone explicitly coming up with a prior. That creates all sorts of practical problems.
Another approach that can avoid some of these downsides that I don’t see used much, but I think would be especially applicable in industry (because it mimics how most other decisions are made in a company) is to change the problem to a social decision rule where you’re trying to convince the most skeptical (reasonable) person.
Suppose there is a set of “reasonable” priors (M)— i.e. the set of prior beliefs a reasonable person could have.
Let P(m) = p map priors m to posteriors p. The idea here is to imagine that your decision solves this problem:
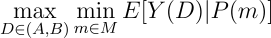
i.e. evaluate each decision by the worst posterior that you can get from the reasonable priors.
This decision rule is intuitive and roughly matches how decisions are made collectively in any case. It’s not really Bayesian. It’s a social decision rule where individual decision-makers are Bayesian but the final decision is made under inconsistent beliefs (we compare the expectation of B under one set of beliefs and A under another set of beliefs).
How might we actually do this in practice:
Suppose priors are M = { Y(B) = N((1+m)u, v), Y(A) = N(u,v) : m(lb) ≤ m ≤ m(ub) }, i.e. priors differ by percentage treatment effects in a single-index so it’s easy to solve for the “worst case”.
In this example, every prior in M has the same prior for Y(A), we just disagree about how effective B is. This is kind of likely to model the actual disagreement within a team (there’s more data about the status quo and people probably roughly agree on how good the status quo is).
So, we just choose m = m(lb) as our prior for the B distribution and compute the posterior, i.e. this approach is very “do-able”. Practical.
The key idea is that it is much easier to agree on the set of Reasonable Priors than to agree on a specific prior. We all might be able to agree, for example, on the largest magnitude of the treatment effect, even if we disagree on the sign (e.g., the change on the site just isn’t large enough to induce an effect size greater in magnitude than 1-2%).
Reasonable Priors could even be set centrally (maybe taking in the largest believable magnitude parameter above as an input) which is difficult to do with specific priors (you can use past experiments but many experiments have only a tangential relationship to prior ones).
Anyway, thought this would be an interesting approach to balance out some of the problems with implementing Bayesian decision-making for experiments. It seems do-able in the wild. Would be neat to try it,
Zach
Connect at: https://linkedin.com/in/zlflynn/ .
If you want my help with any Experimentation, Analytics, etc. problem, click here.
(Image at top from Wikipedia)
{kind=link}