
Instead Of Testing For Sample Ratio Mismatch (SRM), Correct For It

Don’t Test, Correct: Robust Experiment Estimation

Sample Ratio Mismatch
If you’ve interacted with any Experimentation Platform, you’ve probably run into the “Sample Ratio Mismatch” (SRM) test. It’s a test for a “problem” where the theoretical allocation of experiment subjects to treatments does not match the actual traffic split in the data. For example, we set up a 50–50 A/B test but get a 45–55 allocation instead.
Many experimentation platforms check for SRM and report tests as invalid if the allocation doesn’t match.
SRM is not a problem itself, exactly. It is a way to detect a problem, but the fact that we enter 50/50 into our experimentation tool and 45/55 comes out is no biggie.
Imagine the Platform distorts your desired split between Treatment and Control by adding 5% to the Treatment and taking 5% from the Control group because somebody introduced a bug in the UI. This would not cause bias in the experiment results because running an A/B test with a 45–55 split is fine.
The Platform checks for SRM because it might indicate that the treatment and control groups are incomparable. This can happen because, conditional on variant assignment, the chance of exposure to the Treatment differs across the variants.
We can split up the two steps in experiment exposure like this:
The Platform assigns a treatment to the user. (Step 1 = Assignment)
The user experiences whatever feature we’re experimenting with. (Step 2 = Exposure)
The problem SRM detects is when the assignment to A or B in Step 1 causes an imbalance in the probability of making it to Step 2. Because many experiment analysis systems analyze the population in Step 2, this creates a bias in the results because the population of users that make it to Step 2 differs between A and B.
SRM indicates that we are marking users entering Step 2 too late in their journey. The user has already been affected by the treatment before reaching what we labeled as the start of Step 2.
SRM is annoying because you only learn of its presence after wasting time running the experiment. It would be much nicer if we were just using an estimator that’s robust to this problem so we don’t waste time.
Step 1 and Step 2 Treatment Effects
Even if a problem causes an imbalance in Step 2, estimating the treatment effect based on the units bucketed in Step 1 is perfectly valid. We might call this an “intent to treat” effect, but the key thing is that it has the same sign as the treatment effect. Why? Because the treatment necessarily has zero effect on all the users who drop off between Step 1 and Step 2 — they never saw whatever changed in the experiment!
The Step 1 Treatment Effect:
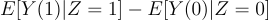
Where Z is the variant assignment.
The problem with the (estimated) Step 1 treatment effect is that if everything is set up correctly so that pr(Step 2 | Z = z) = pr(Step 2), then it is underpowered because it captures noise in the metrics from people who were never exposed to the experiment.
The Step 2 Treatment Effect:
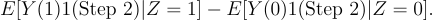
The Step 2 treatment effect forces the treatment effect to be zero for users who never make it to Step 2. The analog estimator uses our knowledge of how the Treatment works. By setting the treatment effect for non-Step 2 users to 0, we cut out the noise in the Step 1 Treatment Effect estimate.
Under correct specification [pr(Step 2 | Z) = pr(Step 2)], Step 1 Treatment Effect and Step 2 Treatment Effect are the same:

The third and fourth terms become, given the independence of Step 2 and Z:
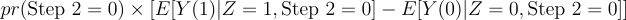
People with Step 2 = 0 never experience the feature we changed, so we know the treatment effect in brackets is 0.
Because:
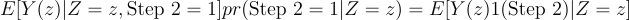
We have:
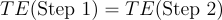
Bringing us to the main point…
Weighted Treatment Effect Estimation
The key idea is to take a weighted average of the unbiased Step 1 treatment effect and the efficient Step 2 treatment effect, following a similar idea to this paper: https://users.ssc.wisc.edu/~bhansen/papers/shrinkiv.pdf (Wisconsin!)
We can select the weights using the test statistic from a hypothesis test that tests the null hypothesis: Step 1 Treatment Effect = Step 2 Treatment Effect. If that hypothesis is correct, we want to put all our weight on the more efficient estimator (Step 2). If not, we want to put all our weight on the consistent but inefficient estimator (Step 1).
This approach has two main advantages over SRM testing:
It offers a solution to the problem instead of telling the experimenter to “start over.”
It focuses on the bias directly instead of on a signal of the bias (SRM).
So, we consider estimators like this:
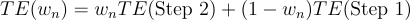
Where:
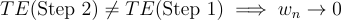
A simple choice for w is:
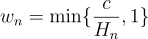
where H(n) is a test statistic that tests the null hypothesis that TE(Step 2) = TE(Step 1), and, under the alternative, H(n) -> infinity.
I don’t want to get too far into the weeds deriving asymptotic distributions here, but you can see that w(n) converges to a distribution on [0,1] if Step 1 = Step 2. The TE is consistent because any weighted sum of Step 1 and Step 2 will be consistent (because the two estimators are equal).
Alternatively, if Step 1 != Step 2, then H(n) -> infinity, so w(n) -> 0 and we use the Step 1 estimator.
The Benefits Relative to SRM Testing
If an SRM test fails, it offers little except a signal that you can’t trust the results. Unless you have incredibly well-powered experiments (you don’t), each experiment represents a significant time investment. Being told to discard and rerun the past four weeks is not the ideal “experimenter experience.”
By correcting for the SRM issue instead, the experimenter still has a chance to make a decision, even if a configuration problem prevents them from getting the most powerful version of the experiment analysis.
If the experiment is a big success (or failure), you’ll detect it even with the Step 1 Estimator. There’s no need to throw the entire experiment out.
Thanks for reading!
Zach
Connect at: https://linkedin.com/in/zlflynn
Read along (or write for!): https://goodenoughstatistics.com
Take my Udemy course!: Identifying Causal Effects for Data Scientists
If you want my help with any Experimentation, Analytics, etc. problem, click here.