
Bounds on Long Run Treatment Effects via d-Surrogacy


The surrogacy problem is:
We want to learn Pr(Y|Z, E) where Y is a metric of interest, Z is variant assignment, and E is the population of interest.
We only know Pr(Z, X | E) and Pr(Y, X | P) where X is a vector of random variables and P is an auxiliary population which does not coincide with E.
The motivation behind the setup is that we have some metric of interest Y that we will not observe until long after the experiment ends (E = experiment population), but we have data prior to the experiment relating Y to some other metrics X that can be observed in the short run (P = pre-experiment population). The goal is to use this relationship to identify the treatment effect on Y.
We can write the distribution as:
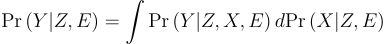
In Athey, Chetty, Imbens, and Kang (ACIK), they make two key assumptions to link what we know to what we want to know:
Comparability: Pr(Y|X, E) = Pr(Y|X, P).
Surrogacy: Pr(Y|Z, X, E) = Pr(Y|X, E).
Applying both assumptions gives: Pr(Y|Z, X, E) = Pr(Y|X, P) where the right hand side is known so the left hand side is identified and:
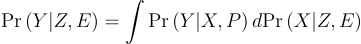
Because we know all the values on the right hand side, Pr(Y|Z, E) is identified.
These are strong assumptions. Under surrogacy, the treatment has no effect on Y except via the “surrogates” (X) observed in population E. Clearly, something like this is needed to point identify the marginal distribution because the only link we have to Y is via Pr(Y|X, P).
Predicting how a metric we do not observe in experiment would have done if it could have been observed is a fundamentally difficult identification problem. The assumptions we need to justify point identification are very strong. After all, the surrogates are essentially trying to predict the future which is a very hard thing to do. It’s difficult to believe the forecast wouldn’t be improved by knowing which variant the experimental unit was assigned to.
ACIK provide error bounds for the case where surrogacy is violated, but maintain comparability in constructing those bounds. When surrogacy is violated, comparability no longer just says P and E are “similar”. The assumption is:
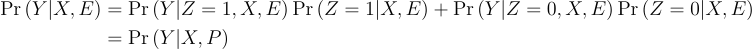
I.e. it places restrictions on violations of surrogacy relative to differences in Pr(Z|X, E) between treatment and control. It is not just an assumption that the relationship between Y and X is “stable” across the E and P populations.
Suppose one of the treatments (Z=0) is the “control” group in the sense that it was the active treatment in the P population. A natural interpretation of the assumption that E and P are comparable populations is that: Pr(Y|Z=0, X, E) = Pr(Y|X, P). In other words, conditional on the treatment that was active in P being active in E, the two populations have the same relationship between Y and X.
But this assumption cannot hold at the same time as Comparability unless:
Surrogacy holds, i.e. Pr(Y|Z=1, X, E) also equals Pr(Y|X, P).
Because, under Comparability, Pr(Y|X, P) is a weighted average of Pr(Y|Z=1, X, E) and Pr(Y|Z=0, X, E). So maintaining Comparability without Surrogacy essentially means we are assuming Pr(Y|Z=0, X, E) does not equal Pr(Y|X, P)! i.e. “Comparability” without Surrogacy implies the control population is not comparable to the pre-experiment population, which is not intuitive.
d-Surrogacy
We can replace the above assumptions with a weaker set of assumptions to bound the treatment effect without maintaining surrogacy:
Control Comparability. Pr(Y|Z=0, X, E) = Pr(Y|X, P). This assumption says that, for the control treatment, Pr(Y|X) is comparable between the two populations. The idea behind the assumption is that the control treatment was active in population P so these two distributions are more plausibly comparable.
d-Surrogacy. Let d(X) > 0. d-Surrogacy assumes that if the difference in mean in the control group is sufficiently large then the difference in mean comparing across treatments has the same sign:
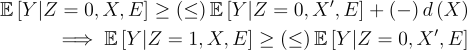
From Control Comparability, we have that:
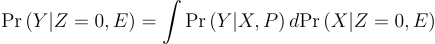
And similarly for the expectation so the mean and marginal distribution of Y for the control group are point identified.
Define:
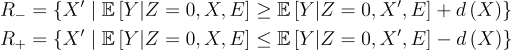
Both of these sets depend only on parameters identified by Control Comparability.
Then, by d-Surrogacy:
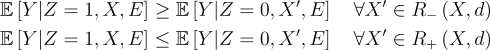
Taking the intersection across the two bounds and applying Control Comparability, we have:
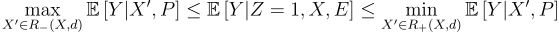
We can write the treatment effect as:
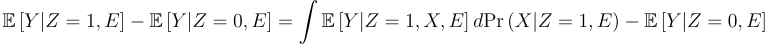
Control Comparability point identifies E[Y|Z=0, E], we observe Pr(X|Z=1, E), and E[Y|Z=1, X, E] is bounded by the above bounds. So we have an upper and lower bound of the treatment effect:
Argument for the Assumptions
Control Comparability is a closer match for the intuition of the assumption that the two populations are comparable than Comparability in the usual case where P = pre-experiment and E = experiment. It says that, because the control treatment is what was happening pre-experiment, the experiment changed nothing in the environment and the two populations are comparable, so the two populations have the same Pr(Y|X). It loses its plausibility if there is no treatment in the experiment that mimics the pre-experiment environment.
d-Surrogacy says that it’s okay for the treatment group to have a different E[Y|X] than the control group, but it cannot be so different that it ranks E[Y|X] and E[Y|X’] differently if the difference between the two is large enough in the control group. Clearly, the first task then is understanding what values of d (“large enough”) are plausible.
The bounds become narrower the smaller d is so it’s helpful to think about what the extreme version of the assumption says when d=0. If E[Y|X, Z=0, E] is differentiable with respect to X and, say, that derivative is positive, we can choose X’ < X and X’’ > X such that ||X’-X|| and ||X’’ — X|| are small and bound E[Y|X’, Z=0, E] < E[Y|X, Z=1, E] < E[Y|X’’, Z=0, E]. Because these are small differences from X, we can take the limit and we’ll get: E[Y|X, Z=1, E] = E[Y|X, Z=0, E], i.e. the surrogacy assumption.
So that is why we need d > 0 to allow Z to have some effect on the distribution. Here are a few plausible options for d.
We can impose a weak assumption like d(X) = sd(Y|X, Z=0, E), i.e. if X’ moves the mean more than a standard deviation away, then we will consider that a large change that won’t be entirely undone by the treatment. This assumption is highly credible for most experiments (unless you happen to be lucky enough to get standard deviation sized wins), and is a good starting point for that reason.
Percentage restriction: d(X; c) = c E[Y|X, Z=0, E]. This means that if the percentage difference between E[Y|X, Z=0, E] and E[Y|X’, Z=0, E] is greater than c, then the order is preserved. The choice of c can be based on intuition about plausible treatment effect sizes conditional on X.
Another intuitive class of choices for d is: d(X; q, c) = c || dE[Y|X, Z=0, E] / dX || . This says that if the difference between E[Y|X, Z=0] and E[Y|X’, Z=0] is larger than the derivative (the linear change for a unit increase in X), then we preserve the order when introducing the treatment.
Any choice of “d” where d > 0 is a weaker assumption than surrogacy so we know we are at least relatively more robust.
Zach
Connect at: https://linkedin.com/in/zlflynn/.
If you want my help with any Experimentation, Analytics, etc. problem, click here.