
A simple workhorse method for picking regression specifications

Clickbait: Never ask whether to use logs or level again!

How should we decide whether to run regressions in logs or levels and make other modeling choices? Read this blog post, and you’ll know one nice way! It’s scintillating. Promise.
We don’t usually have good reasons for running regressions in logs or levels—at least not that we articulate. The truth is that we run the regression, and if the results look funky, we try it the other way. Don’t tell the “stakeholders” the truth, though, or they won’t believe we’re scientists anymore, and then the whole thing falls apart. We have to keep this a secret.
We do such things because there really isn’t a good reason to run stuff in logs or levels, in particular. We’re just trying to model a conditional mean, and there’s rarely a good intuition for functional form. Both seem reasonable enough.
My general (bad) instinct is that with any decision where I don’t have a good reason to pick one thing or the other, I just… don’t choose. Pity my wife asking me about dinner. The good news is that — unlike “do you want cheese on it” — we have a nice way to dodge the question.
The log vs level problem
We want to estimate E[Y|X], and we’re considering using two models to approximate it. This problem is more general than logs vs. levels, but I think it helps to have something concrete to latch onto.
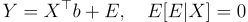
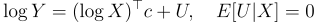
In the first model (the “level” model): E[Y|X] = X’b
In the second model (the “log” model): E[Y|X] = exp(log X’ c) E[exp(U)|X].
So, after estimation, we have two competing models for prediction. How do we choose? There’s a very nice solution.
Rather than using model selection (methods that try to pick the best model), I like to use model averaging (methods that choose weights on models). The reason is pretty simple: model averaging can do model selection by just putting 100% weight on one of the models. The fact that it doesn’t (usually) suggests selection isn’t the way to go.
So, our final prediction of E[Y|X] will be a weighted average of the log and level models:
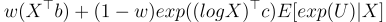
One complication with the log models is the E[exp(U)|X] term. There are a lot of ways to deal with this. One is to assume U is independent of X. We’ve already assumed that log U is mean independent of X, so maybe this isn’t much of a jump. Then the estimator is just the average of the exponential of the residuals from the log model. Another common approach is to run OLS for exp(U) on X and take fitted values. The point is that we need an estimator for that factor. Let’s call it M(X).
A simple method to choose the weights is to minimize the leave-one-out cross-validation mean-squared error criterion.
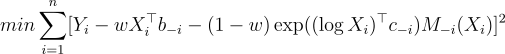
You might think that leave-one-out would take a while to compute, but in this context, it’s very quick because there’s a handy-dandy formula for the leave-one-out coefficient in OLS, see https://robjhyndman.com/hyndsight/loocv-linear-models/. So it’s usually a pretty quick procedure.
Plus, we only need to compute the leave-one-out parameters once while searching for the weights because the weight selection problem can be written as a quadratic programming problem like so:
Stack all leave-one-out predictions into an N x 2 matrix with typical row F(i).
The objective function is then: (Y — Fv)’(Y-Fv) where v= [w, 1-w].
Re-arranging, we get: Y’Y — 2Fv + v’F’Fv
So we can solve for v by solving a standard quadratic programming problem with the constraint that v(j) ≥ 0 and sum v(j) = 1.
And that’s it, now we’ve got weights that we can use to look at derivatives, predictions, etc, in:
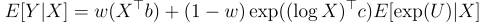
General Problem
You’ll notice there’s actually not too much particular to the log vs level problem above. We could do the same thing for any set of models. It’s most convenient for linear models fit by OLS because leave-one-out predictions are easiest there, but even that’s unnecessary.
In practice, I’ve found that this estimator outperforms much more complicated, flexible “ML” type models, and I think I know why.
There’s data in a modeling problem that doesn’t show up in a SQL query or a CSV file. The data is in your head. You have some idea about how your industry works and what the most relevant features are — maybe you even have a little insight on what the functional form should look like. You can come up with a bunch of “reasonable” models. A flexible ML model has to use the data alone to determine what features and functional forms to use.
By forcing the weights on these reasonable models to be positive and sum to 1, you end up choosing a model that’s a convex combination of a bunch of reasonable models. So, the resulting model is usually well-behaved and doesn’t chase after noise like in more flexible ML models. At the same time, it still leverages data to help build the model by choosing the weights so it’s incremental relative to your intuition about what the right model looks like.
Anyway, hope it’s a neat tool for your toolbox that you might use at some point.
Thanks for reading!
Zach
Connect at: https://www.linkedin.com/in/zlflynn/
Check out my Udemy course at: https://www.udemy.com/course/identifying-causal-effects-for-data-scientists/?couponCode=CHEAPCAUSALINF2
If you want my help with any Experimentation, Analytics, etc. problem, click here.